Virtual Memory
PCB, Context Switch 등등의 메모리 관리 기법에서는 메인 메모리에 프로그램이 전체적으로 load 되는 것을 전제로 한다.
하지만 사실은 부분적으로 load 되어도 프로세스로 실행이 된다는 것!
고급 자원인 CPU 이용률을 올리기 위해서는 많은 프로그램을 Main Memory에 올리는 것이 중요하다.
가상 메모리의 장점
- CPU 이용률과 처리량을 향상 시킴
- loading과 swapping하는 I/O 시간을 줄임
- 모든 프로그램이 모두 load/swap 될 필요 없으니까!
- Response time 또한 줄일 수 있음

프로그램 A,B,C가 있다고 할 때 일부만 올린다. 3개의 프로그램이 모두 다 올라왔다고 생각하겠지 아니다. 그래서 가상 메모리라고 부른다.
Demand Paging과 Demand Segmentation을 통해 가상 메모리를 구현한다. 그 중 페이징 기법을 사용하는 방법을 예시를 들겠다.
Demand Paging
program이 다음과 같이 있을 때 Page 1,2,3 중 1만 Main memory에 올려둔 상태다. CPU가 이를 실행 시키다가 1번 page 실행이 완료 되면 2번 page를 Main memory에 load하기 위한 demand가 발생한다.
Page가 필요한 경우에만 해당 page를 Main Memory에 load한다.
- 사용되지 않을 page는 적재되지도 않음
- I/O가 적게 걸림
- 메모리를 덜 사용함
- 빠른 응담
Locality(지역성)
cpu가 1번 page를 실행하고 있을 때 명령어가 끝나면 옆 명령어, 그 다음 명령어, ... 이런 식으로 실행된다.
이렇게 참조 할 때 지역성이 있어서 demand paging이 가능하다!
Pure Demand Paging
처음 프로세스를 실행할 때 메모리에 아무런 페이지를 load하지 않고 시작하는 방법
실행 동시에 page fault가 발생한다.
Valid-Invalid Bit
Page가 Memory에 적재되어 있지 않은 지를 나타내기 위해 bit로 표시한다.
bit가 0이면 memory에 없는 것이고, 1이면 load되어 있는 상태를 뜻한다.
주소 변환이 일어날 때 이 valid-invalid bit가 0이면 해당 페이지를 memory로 가져오기 위해 page fault가 일어난다
프로세스가 page D (3500번지)를 접근하려고 할때 가장 앞 숫자인 3번의 페이지를 페이지 테이블에서 확인한다. 페이지 테이블에서 확인 결과 invalid하다(=memory에 없다)는 것을 확인하니 page fault가 발생한다.
page fault를 해결하는 방법은 main memory에 해당 페이지를 load 시키는 것이다.
전체적인 그림을 보면 아래와 같다.
- page table에서 page bit를 확인 -> invaild 인 경우
- Trap (interrupt) 발생 -> ISR 실행
- 기존 실행되고 있던 프로세스의 상태를 PCB에 저장
- 다음 실행할 주소가 access 가능한지 확인(3500번)
- disk에서 비어있는 frame에 가져와서 load
- 이 작업들을 하는 동안 CPU를 다른 프로세스(B)에게 할당해 줌
- 해당 작업이 끝나면 I/O가 끝났다는 interrupt를 걸어줌
- 프로세스 B의 상태를 PCB에 저장
- page table에 해당 page를 valid로 변경 (memory에 이제 적재 됐으니)
- 해당 페이지를 실행하는 작업을 다시 실행
- 프로세스 A의 기존 상태를 PCB에서 다시 load
- interrupt 당했던 부분부터 프로세스 A 실행
정리
Demand paging 기법을 사용하면서 muti programming degree(=Main memory에서 돌아가는 program의 개수)를 높일 수 있다.
이를 통해 CPU 이용량과 처리량을 증가시킨다.
☝️ 하지만
필요한 부분을 disk에서 찾아서 Main memory로 load하려는데 main memory에 빈자리가 없으면?
여기서 나온게 Page Replacement
Page Replacement

페이지 교체를 하려면 어떤 page(이런 교체 당하는 페이지를 victim이라고 부름)를 메모리에서 swap out을 할 지 정해야한다. swap in을 할 때는 오래 걸려도 필수적으로 disk로부터 load되어야 하기 때문에 선택지가 없지만, swap out을 할 때는 만약 page가 변경된 사항이 없으면 굳이 복사를 안해도 되고 생략이 가능하다.
따라서 이렇게 페이지가 변경되었는지 여부를 확인하기 위해 Modify bit를 사용한다.
이런 페이지 교체는 여러 알고리즘들이 있다.
Page Replacement Algorithm
1. FIFO 페이지 교체

가장 구현이 간단한 FIFO 알고리즘이다.
가장 오래된 page가 victim으로 선정되어 교체된다.
하지만 성능은 좋지 않음!

reference string은 어떤 page를 참조하는 지를 뜻한다.
위와 같이 FIFO 알고리즘을 통해 교체된다.
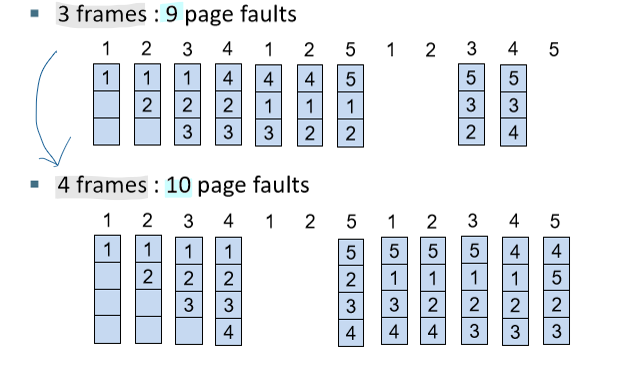
💡Belady's Anomaly
밑 그림처럼 프레임이 증가하는데, page fault 가 증가하는 이상한 현상이 발생하기도 한다.
2. Optimal 페이지 교체
가장 오랜 기간동안 사용되지 않을 페이지를 교체하는 알고리즘
미래를 예측할 수 없기에 구현할 수 없지만 최적인 알고리즘이다.
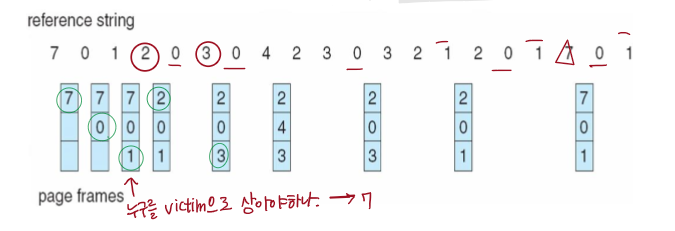
미래를 알 수 없으니, 과거를 참고하는 것이 LRU 알고리즘
3. LRU(Least Recently Used
가장 오랫동안 사용되지 않은 페이지를 교체하는 알고리즘

성능이 좋기 때문에 가장 많이 사용된다!
Belady's Anomaly 또한 없다.
하지만 Least Recently Used Page를 따로 저장해야하기 때문에 추가적인 자료구조도 필요하다.
즉, 추가적인 h/w적인 자원이 필요하다
ex) 사진 어플

3-1 LRU의 구현
LRU는 크게 2가지로 구현된다.
🔹 3-1-1. Counter Imlementation
page table 안 time-of-use field를 추가한다.
CPU에는 Counter라는 논리적 clock을 가지고 있다. 메모리를 참조할 때마다 clock을 이용해서 마지막으로 참조된 시간을 저장한다.
time-of-use field가 가장 작은 page가 가장 오래된 page기 때문에 victim으로 선정되어 교체된다.
다시 말해서, 이 방법을 적용하려면 CPU 내 clock이 유지ㄷ가 되고, 자동으로 증가하는 기능이 있어야 한다.

🔹 3-1-2. Stack Implementation

페이지가 참조되면, stack에서 제거되고 가장 위에 push된다. 따라서 가장 최근에 참조한 page는 항상 stack 맨 꼭대기에 있다.

위 상황에서는 가장 아래에 있는 4번이 victim으로 선택된다. 원래 같으면 stack은 가장 위에서만 pop되지만, 여기서는 특별히 아래에서도 pop이 가능한 스택을 사용한다.
정리
LRU는 H/W적인 지원이 없으면 구현할 수 없다. 하지만 Reference bit라는 것을 이용해서 흉내낼 순 있다. 그렇게 해서 나온게 LRU Approximation Algorithms!
4. LRU Approximation Algorithms

대부분의 system은 Page Table에 Reference bit를 제공한다. 0이라는 것은 특정 시간동안 참조 되지 않았다는 뜻이다. 따라서 당연히 1인 것은 교체 대상이 되면 안된다. 하지만 무엇이 가장 오랫동안 참조되었는지는 모른다.
이것을 사용해서 특별한 H/W적인 자원 없이 LRU를 흉내낸 것이 LRU Approximation Algorithm이다.
LRU Approximation Algorithms 은 크게 Additional-Reference-Bits Algorithm,Second-Chance Algorithm Enhanced Second-Chance Algorithm 3가지가 있다.
4-1. Additional-Reference-Bits Algorithm
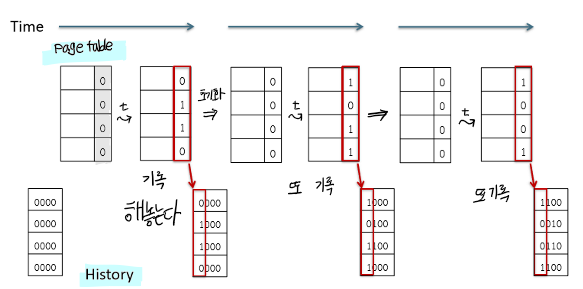
시스템에서 제공하는 reference bit들을 기록해놓으면서 가장 적은 숫자를 가진 page를 victim으로 선정한다.
4-2. Second-Chance Algorithm
기본적으로는 FIFO 방식이지만, 최근에 참조가 됐다고 하면 한 번 봐주는 식으로 진행된다.

Reference bit가 1이면 참조가 된 것이니까 무조건 봐주는 것!
여기서 개선을 더 한게 Enhanced Second-Chance Algorithm
4-3. Enhanced Second-Chance Algorithm
modify bit도 추가 해서 Reference bit와 함께 둘다 사용해서 개선을 한 것이다.

replace할 page의 bit가 0이니, 원래 같았음 얘를 victim으로 삼았겠지만. modify bit =1 이다.
modified 됐다는 거니까 disk에 반드시 write을 해야한다.
modified = 0 은 write하는 걸 생략할 수 있으니 이 것을 교체하는 게 낫다!
5. Counting Algorithms
각 페이지마다 참조하는 횟수(Count)를 저장하는 알고리즘
5-1 LFU (Least Frequently Used) Algorithm
가장 작은 Count를 가진 페이지로 교체한다.
5-2 MFU(Most Frequently Used) Algorithm
가장 작은 Count를 가진 페이지는 얼마 전에 가져왔으므로 아직 참조할 것이 남았을 거라고 생각하고 가장 큰 Count를 가진 페이지로 교체한다.
두 알고리즘 모두 성능이 좋지는 않다. (LRU가 최고 😊)
'‡Computer Science ‡ > º 운영체제' 카테고리의 다른 글
| [운영체제] 동기화(Process Synchronization) (0) | 2024.07.08 |
|---|---|
| [운영체제] PCB와 Context Switching (0) | 2024.06.27 |
| [운영체제] 인터럽트와 시스템 콜 (0) | 2024.06.27 |